Tuning Analytics Database
Below are the guidelines for a fully scalable analytics database designed to efficiently crawl through hundreds of millions of analytics entries.
| Failing to following these steps may compromise overall solution performance. |
There are three required steps for fine tuning the database.
-
Analytics Independent Database
-
Analytics Table partitioning
-
Analytics Table indexing
| All steps must be properly executed for a performant analytics and dashboard component. In some cases these changes increased performance by up to 95% when tested against a non optimised database. |
Hardware Specifications
For optimal performance of the analytics database, the following hardware specifications are recommended:
-
CPUs: 8
-
RAM: 32 GB
-
Disk: Capable of supporting 12,000 IOPs and a minimum read speed of 300 MB/s.
Analytics Independent Database
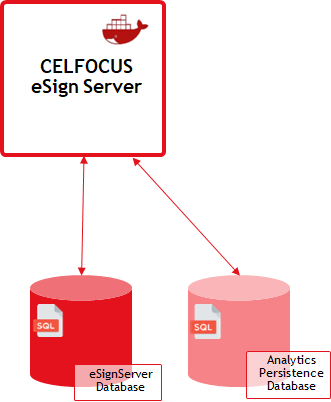
In order to enhance our data analytics capabilities and ensure optimal performance, it is imperative to create a new Analytics database. This new database will serve as the centralized repository for all analytics-related data and will be instrumental in streamlining our analytics workflows.
Rationale for Separating Analytics Data
Performance Isolation Isolating analytics queries from transactional queries ensures that resource-intensive analytics operations do not adversely affect the performance of the main application.
Scalability A dedicated database for analytics data allows for independent scaling, thereby accommodating growing analytics needs without impacting the primary application database.
Resource Optimization Different databases can be fine-tuned for specific workloads, which leads to more efficient utilization of resources and improved overall system performance.
Configure eSign
In addition to creating a new Analytics database, it’s crucial to configure two persistence units that will handle database operations. These units are named analytics and analytics-reader.
analytics: This unit is responsible for all write operations to the Analytics database. It will handle tasks such as inserting and deleting records.
analytics-reader: This unit is designated for read operations from the Analytics database. It will handle tasks like querying the database and fetching records.
Both persistence units must be connected to the new Analytics database to ensure a cohesive data management strategy.
Example
{
"database.url": "jdbc:databasesystem://esign-host:port;database=esign",
"database.user": "esign",
"database.password": "esign-password",
"database.analytics.url": "jdbc:databasesystem://analytics-host:port;database=analytics",
"database.analytics.user": "analytics",
"database.analytics.password": "analytics-password",
"database.analytics-reader.url": "jdbc:databasesystem://analytics-host:port;database=analytics",
"database.analytics-reader.user": "analytics",
"database.analytics-reader.password": "analytics-password"
}|
The persistence unit name ( |
Partitioning Analytics Tables in Analytics Database
|
Backup Your Data: Before proceeding with the partitioning process, it is crucial to backup all data. Failure to do so may result in data loss or corruption. |
Why Partition These Tables?
Improved Query Performance Partitioning allows the database engine to read from a subset of the data, thereby reducing I/O operations and improving query performance.
Efficient Data Management Partitioning simplifies data management tasks such as data archiving, purging, and backups. It allows for operations to be performed on individual partitions rather than the entire table.
Scalability As data grows, partitioning ensures that the system can handle larger datasets more efficiently by distributing the load across multiple partitions.
Tables and Partitioning Columns
The following tables are to be partitioned based on specific date columns:
-
analytics_signature: Partitioned byaction_date -
analytics_artifact: Partitioned byaction_date -
analytics_user: Partitioned bylogin_date
Partitioning Strategy: Yearly Partitioning
The recommended partitioning strategy for these tables is to create partitions based on years. Each partition will contain data for a specific year, making it easier to manage and query.
Maintenance and Future Planning
Proper maintenance of these partitions is essential for continued performance benefits. New partitions should be created before the start of each new year to ensure that data for the upcoming year has a dedicated partition. Failure to do so could lead to performance degradation and complicate data management tasks.
Hardware Considerations
While partitioning is primarily a software operation, it’s important to ensure that the underlying hardware can support the increased I/O operations that may result from partitioning. Please refer to the hardware specifications mentioned in the previous section for optimal performance.
By implementing this partitioning strategy, you can expect to see significant improvements in query performance, data management, and overall system scalability.
|
Expertise and Adaptation Required, the sample scripts provided in the sections belows are examples and should be executed by someone who understands Database partitioning. Different database versions will most likely have different nuances and ways of applying the sampled scripts! Additionally, the partitioning years in the scripts should be adapted to match the current data in your tables. |
Sample Partitioning Scripts for Analytics Database
|
Data Backup Precaution Before proceeding with the partitioning process, it is crucial to backup all data. Failure to do so may result in data loss or corruption. |
SQL Server
Below are SQL Server scripts to implement partitioning on the existing tables analytics_signature, analytics_artifact, and analytics_user. These scripts also create new clustered indexes that utilize the partition scheme.
|
Filegroup Specification
The scripts use |
Show/Hide Script
-- Create Partition Function for analytics_signature
CREATE PARTITION FUNCTION pf_analytics_signature (datetime)
AS RANGE RIGHT FOR VALUES ('20220101', '20230101', '20240101');
-- Create Partition Scheme for analytics_signature
CREATE PARTITION SCHEME ps_analytics_signature
AS PARTITION pf_analytics_signature ALL TO ([PRIMARY]);
-- Create New Clustered Index for analytics_signature
CREATE CLUSTERED INDEX idx_analytics_signature_partitioned
ON analytics_signature (action_date)
ON ps_analytics_signature (action_date);
-- Create Partition Function for analytics_artifact
CREATE PARTITION FUNCTION pf_analytics_artifact (datetime)
AS RANGE RIGHT FOR VALUES ('20220101', '20230101', '20240101');
-- Create Partition Scheme for analytics_artifact
CREATE PARTITION SCHEME ps_analytics_artifact
AS PARTITION pf_analytics_artifact ALL TO ([PRIMARY]);
-- Create New Clustered Index for analytics_artifact
CREATE CLUSTERED INDEX idx_analytics_artifact_partitioned
ON analytics_artifact (action_date)
ON ps_analytics_artifact (action_date);
-- Create Partition Function for analytics_user
CREATE PARTITION FUNCTION pf_analytics_user (datetime)
AS RANGE RIGHT FOR VALUES ('20220101', '20230101', '20240101');
-- Create Partition Scheme for analytics_user
CREATE PARTITION SCHEME ps_analytics_user
AS PARTITION pf_analytics_user ALL TO ([PRIMARY]);
-- Create New Clustered Index for analytics_user
CREATE CLUSTERED INDEX idx_analytics_user_partitioned
ON analytics_user (login_date)
ON ps_analytics_user (login_date);PostgreSQL
|
The following script replaces the original table by a partitioned one, if all goes well there will be a table preceded by the old_prefix. The script does not drop the original table on purpose to prevent copy paste disasters, once and only once you have confirmed that all is as it should can you manually use the drop table command. |
Show/Hide Script
-- Drop the existing primary key constraint
ALTER TABLE analytics_signature DROP CONSTRAINT pk_analytics_signature;
-- Add the new primary key constraint that includes id and action_date
ALTER TABLE analytics_signature ADD CONSTRAINT pk_analytics_signature PRIMARY KEY (id, action_date);
-- Create new partitioned tables
CREATE TABLE new_analytics_signature (LIKE analytics_signature INCLUDING ALL) PARTITION BY RANGE (action_date);
CREATE TABLE analytics_signature_2022 PARTITION OF new_analytics_signature FOR VALUES FROM ('2022-01-01') TO ('2023-01-01');
CREATE TABLE analytics_signature_2023 PARTITION OF new_analytics_signature FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
-- Populate new partitioned tables with data from old table
INSERT INTO new_analytics_signature SELECT * FROM analytics_signature;
-- Create indexes on new partitioned tables
CREATE INDEX idx_analytics_signature_2022 ON analytics_signature_2022 (action_date);
CREATE INDEX idx_analytics_signature_2023 ON analytics_signature_2023 (action_date);
-- Verify row counts between old and new tables
DO $$
DECLARE
old_count INTEGER;
new_count INTEGER;
BEGIN
SELECT COUNT(*) INTO old_count FROM analytics_signature;
SELECT COUNT(*) INTO new_count FROM new_analytics_signature;
IF old_count = new_count THEN
-- Rename or drop old table
ALTER TABLE analytics_signature RENAME TO old_analytics_signature;
-- Rename new table
ALTER TABLE new_analytics_signature RENAME TO analytics_signature;
END IF;
END $$;
-- Drop the existing primary key constraint
ALTER TABLE analytics_artifact DROP CONSTRAINT pk_analytics_artifact;
-- Add the new primary key constraint that includes id and action_date
ALTER TABLE analytics_artifact ADD CONSTRAINT pk_analytics_artifact PRIMARY KEY (id, action_date);
-- Create new partitioned tables
CREATE TABLE new_analytics_artifact (LIKE analytics_artifact INCLUDING ALL) PARTITION BY RANGE (action_date);
CREATE TABLE analytics_artifact_2022 PARTITION OF new_analytics_artifact FOR VALUES FROM ('2022-01-01') TO ('2023-01-01');
CREATE TABLE analytics_artifact_2023 PARTITION OF new_analytics_artifact FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
-- Populate new partitioned tables with data from old table
INSERT INTO new_analytics_artifact SELECT * FROM analytics_artifact;
-- Create indexes on new partitioned tables
CREATE INDEX idx_analytics_artifact_2022 ON analytics_artifact_2022 (action_date);
CREATE INDEX idx_analytics_artifact_2023 ON analytics_artifact_2023 (action_date);
-- Verify row counts between old and new tables
DO $$
DECLARE
old_count INTEGER;
new_count INTEGER;
BEGIN
SELECT COUNT(*) INTO old_count FROM analytics_artifact;
SELECT COUNT(*) INTO new_count FROM new_analytics_artifact;
IF old_count = new_count THEN
-- Rename or drop old table
ALTER TABLE analytics_artifact RENAME TO old_analytics_artifact;
-- Rename new table
ALTER TABLE new_analytics_artifact RENAME TO analytics_artifact;
END IF;
END $$;
-- Drop the existing primary key constraint
ALTER TABLE analytics_user DROP CONSTRAINT pk_analytics_user;
-- Add the new primary key constraint that includes id and login_date
ALTER TABLE analytics_user ADD CONSTRAINT pk_analytics_user PRIMARY KEY (id, login_date);
-- Create new partitioned tables
CREATE TABLE new_analytics_user (LIKE analytics_user INCLUDING ALL) PARTITION BY RANGE (login_date);
CREATE TABLE analytics_user_2022 PARTITION OF new_analytics_user FOR VALUES FROM ('2022-01-01') TO ('2023-01-01');
CREATE TABLE analytics_user_2023 PARTITION OF new_analytics_user FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
-- Populate new partitioned tables with data from old table
INSERT INTO new_analytics_user SELECT * FROM analytics_user;
-- Create indexes on new partitioned tables
CREATE INDEX idx_analytics_user_2022 ON analytics_user_2022 (login_date);
CREATE INDEX idx_analytics_user_2023 ON analytics_user_2023 (login_date);
-- Verify row counts between old and new tables
DO $$
DECLARE
old_count INTEGER;
new_count INTEGER;
BEGIN
SELECT COUNT(*) INTO old_count FROM analytics_user;
SELECT COUNT(*) INTO new_count FROM new_analytics_user;
IF old_count = new_count THEN
-- Rename or drop old table
ALTER TABLE analytics_user RENAME TO old_analytics_user;
-- Rename new table
ALTER TABLE new_analytics_user RENAME TO analytics_user;
END IF;
END $$;Oracle
|
The following script replaces the original table by a partitioned one, if all goes well there will be a table preceded by the old_prefix. The script does not drop the original table on purpose to prevent copy paste disasters, once and only once you have confirmed that all is as it should can you manually use the drop table command. |
Show/Hide Script
CREATE TABLE analytics_signature_test (
"ID" NUMBER(38,0) GENERATED BY DEFAULT AS IDENTITY MINVALUE 1 MAXVALUE 9999999999999999999999999999 INCREMENT BY 1 START WITH 1 CACHE 20 NOORDER NOCYCLE NOKEEP NOSCALE NOT NULL ENABLE,
-- [rest of the columns in analytics_signature table]]
CONSTRAINT "PK_ANALYTICS_SIGNATURE_TEST_NEW" PRIMARY KEY ("ID")
) PARTITION BY RANGE (action_date) (
PARTITION analytics_signature_test_2022 VALUES LESS THAN (TO_DATE('2023-01-01', 'YYYY-MM-DD')),
PARTITION analytics_signature_test_2023 VALUES LESS THAN (TO_DATE('2024-01-01', 'YYYY-MM-DD'))
);
-- Populate new partitioned tables with data from old table
INSERT INTO analytics_signature_test SELECT * FROM analytics_signature;
-- Create local indexes on the new partitioned table
CREATE INDEX idx_analytics_signature_test ON analytics_signature_test (action_date) LOCAL;
-- Verify row counts between old and new table partitions
DECLARE
old_count NUMBER;
new_count NUMBER;
BEGIN
SELECT COUNT(*) INTO old_count FROM analytics_signature;
SELECT COUNT(*) INTO new_count FROM analytics_signature_test; -- The table itself remains the same, just partitioned
IF old_count = new_count THEN
DBMS_OUTPUT.PUT_LINE('Row counts match. Partitioning was successful.');
-- Rename or drop old table
ALTER TABLE analytics_signature RENAME TO old_analytics_signature;
-- Rename new table
ALTER TABLE analytics_signature_test RENAME TO analytics_signature;
END IF;
END;
CREATE TABLE analytics_artifact_test (
"ID" NUMBER(38,0) GENERATED BY DEFAULT AS IDENTITY MINVALUE 1 MAXVALUE 9999999999999999999999999999 INCREMENT BY 1 START WITH 1 CACHE 20 NOORDER NOCYCLE NOKEEP NOSCALE NOT NULL ENABLE,
-- [rest of the columns in analytics_artifact table]]
CONSTRAINT "PK_ANALYTICS_ARTIFACT_TEST_NEW" PRIMARY KEY ("ID")
) PARTITION BY RANGE (action_date) (
PARTITION analytics_artifact_test_2022 VALUES LESS THAN (TO_DATE('2023-01-01', 'YYYY-MM-DD')),
PARTITION analytics_artifact_test_2023 VALUES LESS THAN (TO_DATE('2024-01-01', 'YYYY-MM-DD'))
);
-- Populate new partitioned tables with data from old table
INSERT INTO analytics_artifact_test SELECT * FROM analytics_artifact;
-- Create local indexes on the new partitioned table
CREATE INDEX idx_analytics_artifact_test ON analytics_artifact_test (action_date) LOCAL;
-- Verify row counts between old and new table partitions
DECLARE
old_count NUMBER;
new_count NUMBER;
BEGIN
SELECT COUNT(*) INTO old_count FROM analytics_artifact;
SELECT COUNT(*) INTO new_count FROM analytics_artifact_test; -- The table itself remains the same, just partitioned
IF old_count = new_count THEN
DBMS_OUTPUT.PUT_LINE('Row counts match. Partitioning was successful.');
-- Rename or drop old table
ALTER TABLE analytics_artifact RENAME TO old_analytics_artifact;
-- Rename new table
ALTER TABLE analytics_artifact_test RENAME TO analytics_artifact;
END IF;
END;
CREATE TABLE analytics_user_test (
"ID" NUMBER(38,0) GENERATED BY DEFAULT AS IDENTITY MINVALUE 1 MAXVALUE 9999999999999999999999999999 INCREMENT BY 1 START WITH 1 CACHE 20 NOORDER NOCYCLE NOKEEP NOSCALE NOT NULL ENABLE,
-- [rest of the columns in analytics_user table]]
CONSTRAINT "PK_ANALYTICS_USER_TEST_NEW" PRIMARY KEY ("ID")
) PARTITION BY RANGE (action_date) (
PARTITION analytics_user_test_2022 VALUES LESS THAN (TO_DATE('2023-01-01', 'YYYY-MM-DD')),
PARTITION analytics_user_test_2023 VALUES LESS THAN (TO_DATE('2024-01-01', 'YYYY-MM-DD'))
);
-- Populate new partitioned tables with data from old table
INSERT INTO analytics_user_test SELECT * FROM analytics_user;
-- Create local indexes on the new partitioned table
CREATE INDEX idx_analytics_user_test ON analytics_user_test (action_date) LOCAL;
-- Verify row counts between old and new table partitions
DECLARE
old_count NUMBER;
new_count NUMBER;
BEGIN
SELECT COUNT(*) INTO old_count FROM analytics_user;
SELECT COUNT(*) INTO new_count FROM analytics_user_test; -- The table itself remains the same, just partitioned
IF old_count = new_count THEN
DBMS_OUTPUT.PUT_LINE('Row counts match. Partitioning was successful.');
-- Rename or drop old table
ALTER TABLE analytics_user RENAME TO old_analytics_user;
-- Rename new table
ALTER TABLE analytics_user_test RENAME TO analytics_user;
END IF;
END;|
New partitions should be created before the start of each new year to ensure that data for the upcoming year has a dedicated partition. Failure to do so could lead to performance degradation and complicate data management tasks. |
Indexing Tables in Analytics Database
Importance of Indexes
Indexes are a critical component for optimizing the performance of analytics queries. Properly designed and aligned indexes can result in up to 95% performance gains in query execution. This is especially true for partitioned tables, where aligned indexes can significantly improve data retrieval times by allowing for partition elimination.
Sample Indexing Scripts for Analytics Database
SQL Server Sample
|
Indexes must be maintained and updated in case more partitions are created. It also assumes that you have created the partition schemes with the same name as in the partitioning samples. |
Show/Hide Script
-- Aligned with ps_analytics_artifact partition scheme
CREATE NONCLUSTERED INDEX idx_analytics_artifact_1
ON analytics_artifact (action, action_date)
INCLUDE (artifact_id, action_time, reason)
ON ps_analytics_artifact (action_date);
-- Aligned with ps_analytics_signature partition scheme
CREATE NONCLUSTERED INDEX idx_analytics_signature_1
ON analytics_signature (artifact_id, action, action_date)
INCLUDE (signature_type)
ON ps_analytics_signature (action_date);
CREATE NONCLUSTERED INDEX idx_analytics_signature_2
ON analytics_signature (artifact_id, action_date)
INCLUDE (username)
ON ps_analytics_signature (action_date);
-- Aligned with ps_analytics_user partition scheme
CREATE NONCLUSTERED INDEX idx_analytics_user_1
ON analytics_user (login_date)
INCLUDE (artifact_id, channel)
ON ps_analytics_user (login_date);
CREATE NONCLUSTERED INDEX idx_analytics_user_2
ON analytics_user (login_date)
INCLUDE (username, user_domain)
ON ps_analytics_user (login_date);PostgreSQL Sample
|
Indexes must be maintained and updated in case more partitions are created. The following PL/pgSQL script will loop through all partitions of the specified parent tables (analytics_artifact, analytics_signature, analytics_user) and create the corresponding indexes on each partition. |
Show/Hide Script
DO $$
DECLARE
table_name text;
BEGIN
-- Create indexes for analytics_artifact partitions
FOR table_name IN (SELECT inhrelid::regclass::text
FROM pg_inherits
WHERE inhparent = 'analytics_artifact'::regclass)
LOOP
EXECUTE 'CREATE INDEX ' || table_name || '_idx1 ON ' || table_name || ' (action, action_date) INCLUDE (artifact_id, action_time, reason)';
END LOOP;
-- Create indexes for analytics_signature partitions
FOR table_name IN (SELECT inhrelid::regclass::text
FROM pg_inherits
WHERE inhparent = 'analytics_signature'::regclass)
LOOP
EXECUTE 'CREATE INDEX ' || table_name || '_idx1 ON ' || table_name || ' (artifact_id, action, action_date) INCLUDE (signature_type)';
EXECUTE 'CREATE INDEX ' || table_name || '_idx2 ON ' || table_name || ' (artifact_id, action_date) INCLUDE (username)';
END LOOP;
-- Create indexes for analytics_user partitions
FOR table_name IN (SELECT inhrelid::regclass::text
FROM pg_inherits
WHERE inhparent = 'analytics_user'::regclass)
LOOP
EXECUTE 'CREATE INDEX ' || table_name || '_idx1 ON ' || table_name || ' (login_date) INCLUDE (artifact_id, channel)';
EXECUTE 'CREATE INDEX ' || table_name || '_idx2 ON ' || table_name || ' (login_date) INCLUDE (username, user_domain)';
END LOOP;
END $$;Oracle Sample
|
Indexes must be maintained and updated in case more partitions are created. |
Show/Hide Script
CREATE INDEX idx_analytics_artifact_1
ON analytics_artifact (action_date, action, artifact_id, action_time, reason) LOCAL;
CREATE INDEX idx_analytics_signature_1
ON analytics_signature (action_date, action, artifact_id, signature_type) LOCAL;
CREATE INDEX idx_analytics_signature_2
ON analytics_signature (action_date, artifact_id, username) LOCAL;
CREATE INDEX idx_analytics_user_1
ON analytics_user (login_date, artifact_id, channel) LOCAL;
CREATE INDEX idx_analytics_user_2
ON analytics_user (login_date, username, user_domain) LOCAL;